
The Rise of Reasoning: Going Beyond Chatbots to Strategic Thinkers
How AI is Evolving from Simple Chat to Strategic Thought, and Why This Changes What's Possible—In a 3-Minute Read
The Gist:
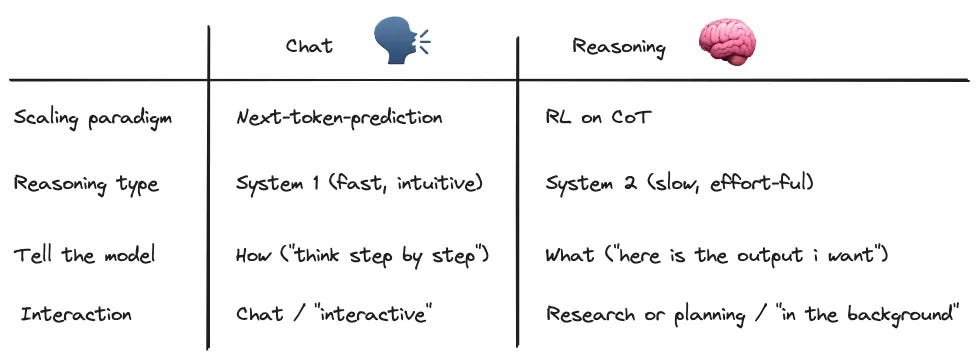
Think of today's AI like two types of thinkers: "System 1" – fast, intuitive, like current chatbots predicting the next word – and "System 2" – slow, deliberate, for complex reasoning. For years, scaling AI meant improving "System 1" via next-word prediction, leading to impressive chatbots. But "System 1" struggles with hard problems needing deeper thought. Enter reasoning models, leveraging "System 2" thinking. These models, like OpenAI's 03, Gemini’s Flash Thinking, and Deep Seek’s R1, are trained to reason step-by-step, not just predict. This shift, powered by Reinforcement Learning on "Chain of Thought," marks a new scaling paradigm, moving AI beyond just sounding smart to actually being strategic.
What Needs to be Understood:
Next Word Prediction (System 1): The current paradigm, models learn by predicting the next word. It's surprisingly powerful, teaching grammar, knowledge, even some math. But it uses the same compute for easy and hard tasks, hitting a bottleneck for complex reasoning. Think of it like multitasking – learning many things at once from a simple objective.
Using Chain of Thought (CoT) to Enforce System 2: CoT prompting is a "hack" to force models towards "System 2" thinking. By prompting "think step-by-step," you make the model produce intermediate steps as tokens. These tokens act like temporary memory, helping the model solve harder problems by breaking them down.
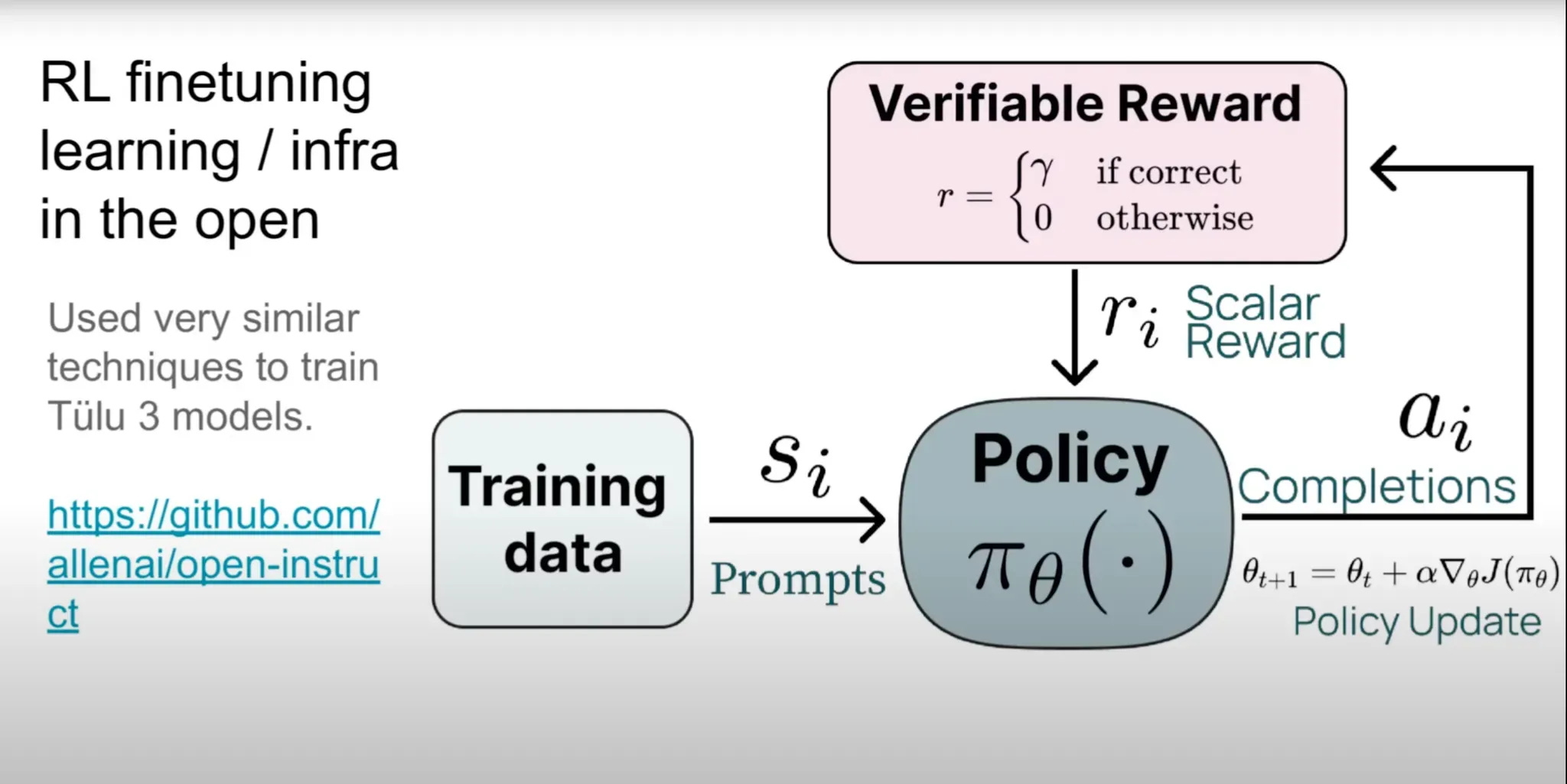
Reinforcement Learning on Chain of Thought (RL-CoT) as The New Paradigm: Reasoning models are trained with Reinforcement Learning. They are rewarded for producing correct answers and the correct reasoning steps (Chain of Thought) leading to those answers.
Training Data & The Grader: Crucially, RL-CoT needs datasets with verifiably correct answers (like coding or math problems) and a "grader" to check if the model's output and reasoning are correct. The model's "policy" (its approach) is adjusted to favor trajectories leading to high rewards.
Observations:
New Scaling Law & Performance: Reasoning models represent a new scaling law, showing rapid progress. Benchmarks are saturating faster, indicating these models are quickly mastering complex tasks. Models like OpenAI’s 03 demonstrate significantly stronger reasoning capabilities.
Don’t Write Prompts; Write Briefs: Unlike chat models where you might guide how to think ("act like a researcher"), with reasoning models, you directly state what you want as the output (e.g., "educational report"). Give context and desired format, but let the model figure out the reasoning.

Use Cases Highlighted:
Coding: Excellent for generating entire files or sets of files in one shot.
Planning & Agents: Ideal for upfront planning in agentic workflows, laying out steps for other AI or processes to follow.
Reflection & Analysis: Deep reflection over large contexts like meeting notes, documents, or research papers.
Data Analysis & Diagnosis: Analyzing complex data like medical tests or for medical reasoning (though privacy is key).
Research & Report Generation: Conducting deep research and generating high-quality reports.
LMs as Judges/Evaluators: Evaluating other AI outputs or processes.
Cognitive Layer for News/Trends: Monitoring trends, filtering news feeds, and surfacing relevant information.
Something to Think About:
Task Fit: Where in your workflows can you leverage reasoning models for tasks needing high quality output?
The Data Bottleneck & The Human-in-the-Loop Solution: The biggest challenge for reasoning AI is acquiring datasets that capture human reasoning processes. Think about how products and workflows could be designed to better capture and verify the steps humans take to solve problems. Could we create tools that make it easier for humans to articulate their reasoning, provide feedback on AI-generated plans, and iteratively improve these models? The companies that crack the code on collecting and leveraging this "reasoning data" will be at the forefront of the next AI wave.
Computational Horizons: While quantum computing is still on the horizon, the broader trend of increasing computational power is directly relevant to reasoning models. As compute capabilities grow, we'll be able to train more complex reasoning models, explore more intricate problem spaces, and potentially even enable AI to consider multiple "hypothetical scenarios" in parallel – much like the potential of quantum computing. What breakthroughs become possible when AI can simulate and evaluate a wider range of potential strategies before acting?
Scaling of Search and Learning: A Roadmap to Reproduce o1 from Reinforcement Learning Perspective

Semianalysis’ Perspective on Scaling O1 Pro Architecture and Reasoning Training Infrastructure
This shift from System 1 to System 2 AI is game changing. Moving from quick predictions to deep reasoning could revolutionize fields like coding, plannin and data analysis. The challenge now is how to capture and validate human reasoning for AI to learn from.
How do you think we can bridge that gap? Would tools to record thought processes work or do we need something more innovative?